This post is the continuation of previous Part I.
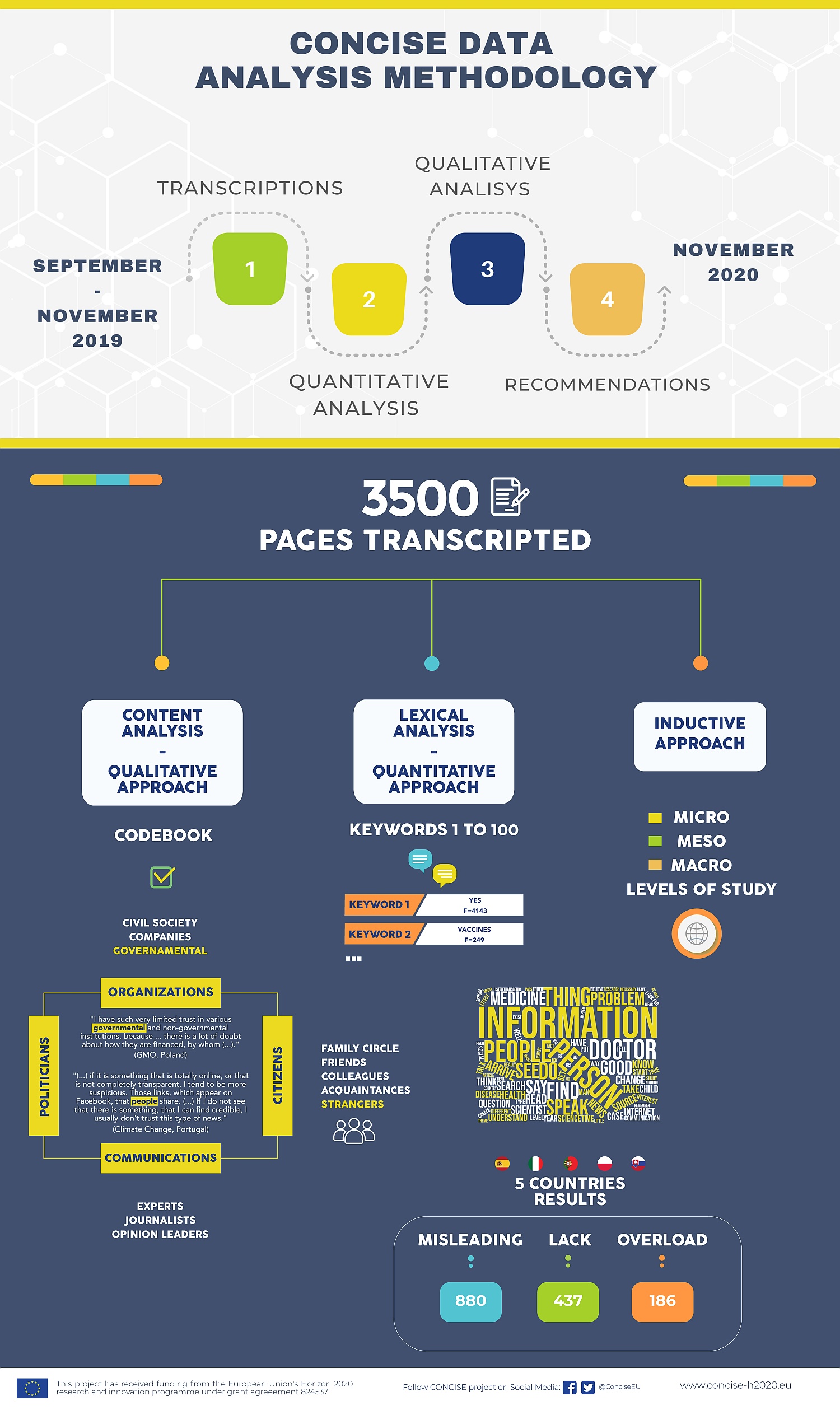
The second step of content analysis was the classical and qualitative one. It follows some fundamental steps, which are also covered in the CONCISE project:
- the choice of the elementary unit.
- the definition of the coding grid.
- the application of the coding grid to the texts.
- the tabulation of the results and/or their interpretation.
Those activities, which we will describe below, are largely subjective since they derive from the researcher’s decisions. The strengths of this classical approach are paradoxically consequent to that discretion. It also seems to constitute its most evident limit: the process of abstraction of the concepts contained in the elementary units and their classification into more general and generalisable categories. In fact, it is strictly the responsibility of the researcher, since the vast range of information available, by its very nature, can only be detected through manual analysis.
- Elementary unit choice. We used the conversational turns as elementary units of analysis. This allowed us to preserve the complexity of the (co-existence of many) concepts participants expressed.
- Coding grid definition. The CONCISE consortium shared a single codebook with a tree structure, as required by the NVivo software. It included both independent (i.e., the topics under discussion and the characteristics of the participants) and dependent (i.e., the contents mentioned by the participants) variables. In the dependent ones, the first branches of the tree contained some nodes transversal to the four topics identified a priori. Then, each branch was populated by other topic-specific codes, emerging from the data during the coding process. In particular, we proposed three main sets of dependent variables a priori, which were coherent with the objectives of the CONCISE project. According to the scripts of the discussions, they were: how citizens get information, the reliability of sources, and proposals to improve science communication. In particular, the dependent variables related to the first aim “how citizens are informed” were their channels and sources. Both represented by many categories of actors (i.e., citizens, communicators, politicians, organisations, institutions, and media). As for the first aim, we also considered: the awareness on the topic, which was defined as the combination of familiarity (level of knowledge, low or high) and engagement (level of interest and sharing, low or high). Also the perception of the information in terms of quantity (e.g. lack or overloading) and quality (e.g. misleading). The dependent variables related to the second aim “reliability of sources” were: the trust/mistrust continuum (i.e. at what level the expectations of the recipient on the science news are placed); and some dimensions characterising communication processes (i.e., credibility, legitimacy, authority, newness, and purpose). As for the second aim, we also considered some forms of evaluation implemented by individuals to assess the reliability of science communication. Some examples of it were: information verification (e.g. deepening and debunking); triangulation of sources (e.g. pluralism of sources used); and personal criteria (e.g. instinct, personal filters, common sense). Finally, the dependent variables related to the third aim «proposals to improve science communication» were populated depending on the specific contents emerging from the texts. Specifically, the coding grid was based on the classic communication models (sender, channel, message, receiver). This allowed us to identify on which aspects the proposals are placed and to deepen the type of recommendations suggested. Then, to answer specific research questions, three areas of action and analysis were taken into account in the coding process, with their many facets: public engagement, co-creation and citizens science.
- Coding grid application. After importing the texts into the NVivo software, the CONCISE partners coded them. We selected all the text passages that we deemed relevant and associated them with one or more pre-existing nodes from the codebook or new ones. Then, we developed a coding hierarchy creating a parent node for the broader theme and child nodes for the specific sub-themes.
- Results tabulation and interpretation. At the end of the coding process, each CONCISE partner produced a summary report. It included a description of the main results organised into five sections. The first section was about the full public consultation, and the other areas were about the four topics discussed. Each section followed the same structure, that is, the node tree shared in the codebook, complemented with the country-specific emerging aspects. In particular, for each branch (and sub-branch) of the node tree, we specified the number of references (i.e. conversational turns) coded with a node, accompanied by some explanatory extracts.
(To be continued)
Authors: Sonia Brondi (Observa) & Carolina Moreno (UVEG).