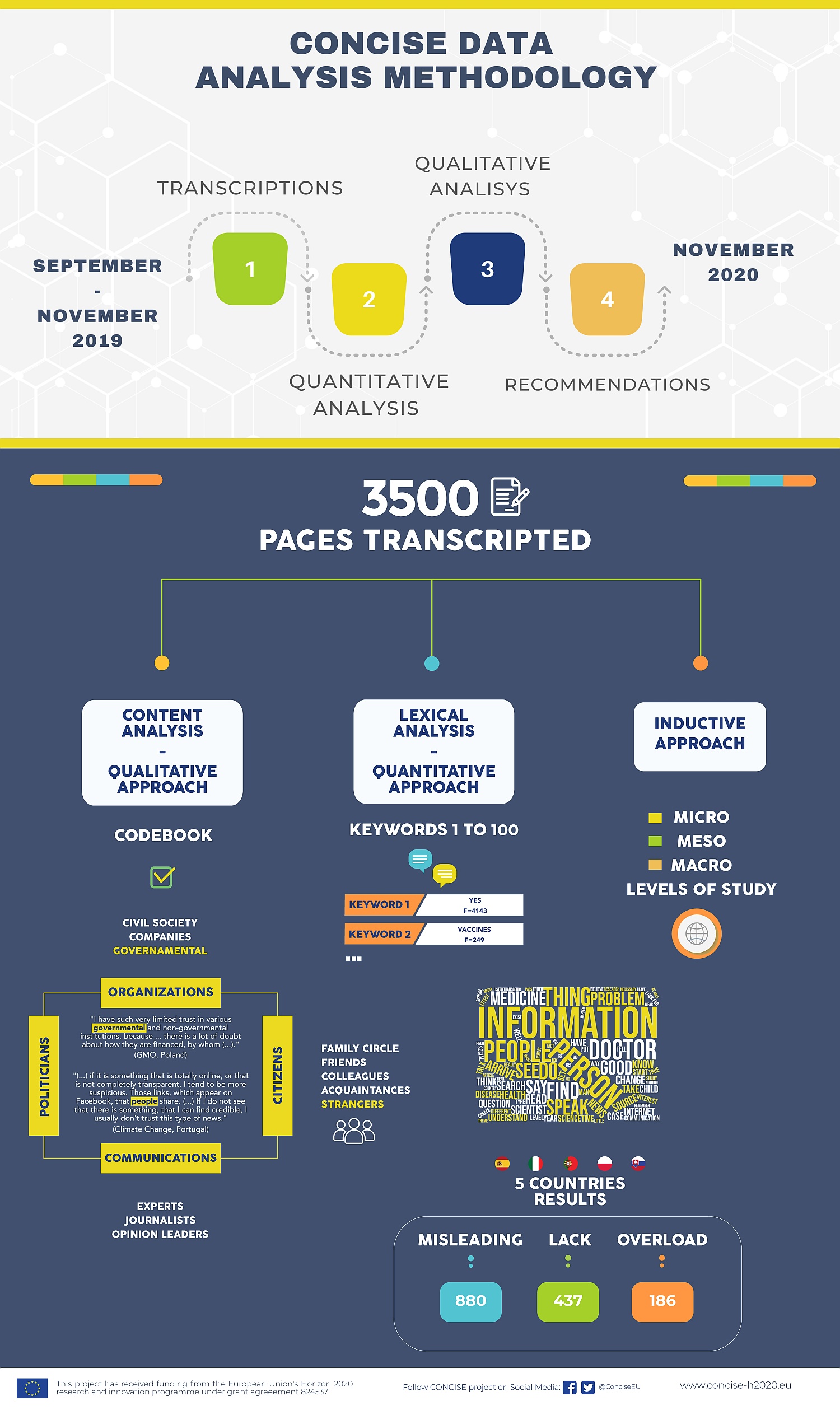
The CONCISE consortium needed a year to analyse the citizens’ speeches deriving from the five CONCISE public consultations. On the one side, we carried out a quantitative analysis based on a lexical-metric approach, and a qualitative research based on a more classical methodological approach. On the other, we analysed the discourses of the citizen consultations focusing on the social aspects of communication and the ways participants used language to achieve specific effects (e.g. to build trust, to create doubt, to evoke emotions, consent or dissent). After coding the transcripts, we analysed the speeches for both levels of the studies. Each form of content analysis responded to specific purposes, following particular procedures and relying on specified software, which we will describe below.
In general, content analysis is a systematic process of acquisition, synthesis and return of the manifest information within a communication, aimed to detect the occurrence of specific themes. The analysis process thus consists on reading all the available information, their organisation, processing and synthesis, to arrive at the restitution finally. That means representing the results in a form suitable to introduce the interpretative keys offered by the researcher (e.g. data matrices or double-entry tables, whose cells report frequencies or scores). The consortium carefully discussed each step to share operative choices and align the analysis procedures.
The first step of the content analysis was the lexical-metric and quantitative one, focused on single words. One advantage is its language-independent approach, especially suitable for comparative cross-country analyses such as that of the CONCISE project. Moreover, its formal process performs the data automatically through fast and straightforward operations managed by dedicated software. It is thus helpful to examine a large amount of data. But, since the choice of the single words as elementary units is rigid, some limits derive. One is the ambiguity of some linguistic expressions and another one is the potential loss of contextual use of some words. From a statistical point of view, the analysis considers the frequency with which single words emerge from discourse and their reciprocal relationships. This lexical-metric approach was structured in a few central moments:
- The preparation of the texts to be analysed
- The computing of textual statistics
- The building of the dictionary
- The specific tools of analysis (i.e. co-occurrence, comparative and thematic analyses).
- Texts preparation. The CONCISE partners prepared the transcripts following strict criteria. We removed from the text any sentence said by the moderators and any comment added by the transcribers. We also checked and corrected any typo. Hence, the first step that was to encode the transcripts. For that purpose, we identified each quote from participants with a code containing information about their table, about the topic debate, gender, age-range, educational level, if they lived in a town or city, and finally, an anonymised code. in the proper format required by the T-Lab software. For instance, * TABLE_ONE * TOPIC_CAM * GENDER_FEMALE * AGE_25TO34 * EDUCATION_SECONDARY * PROVENANCE_URBAN * PARTICIPANT_1038086504.
- Textual statistics computing. After importing the resulting file in the T-Lab software, we selected the language and defined some pre-processing options to limit data dispersion. We converted the inflected forms of each word into their common root with which they appear in the dictionary (e.g., infinitive verbs, singular names; i.e. lemmatisation), and removed ‘empty’ words (e.g., prepositions, articles, conjunctions; i.e. stop-word check). Then, the software calculated the number of conversational turns, words (i.e. occurrences), different words (i.e. forms), single-occurrence words (i.e. hapaxes) and their mutual proportions. With that preliminary information we verified the adequateness of the data for further analyses.
- Dictionary building. The software created the list of the retained words in alphabetical and occurrence order. We verified the correct recognition of the words, selected the words mentioned at least ten times (i.e. keywords), and visualised a word-cloud with the most recurring keywords from each public consultation. This provided an initial representation of the most common themes discussed.
- Analysis tools. First, the co-occurrence analyses allowed us to perform a network analysis of the relationships among the keywords and to visualise a graph. Second, the comparative analyses allowed us to conduct a specificity analysis of the characteristic or exclusive keywords of a modality of a variable (e.g., the keywords more or only said by men than women). Third, the thematic analyses allowed us to run both cluster and correspondence analyses. The cluster analysis identified thematic groups defined by keywords and modalities of variables. The CONCISE consortium interpreted those thematic clusters as different forms of communication in which science-related information is embedded (e.g., daily, health, public, institutional, expert communication). The correspondence analysis identified bipolar dimensions, defined by keywords and modalities of variables, that organise discourse. Considering these dimensions as the axes of a factorial space, we could visualise a graphical representation of the words and the positioning of the groups of participants. The CONCISE consortium interpreted those semantic axes as main dimensions underlying trust in science communication (e.g., private vs public, active vs public, mediated vs direct, expert vs lay, theoretical vs abstract).
At the end of this phase, each CONCISE partner produced two reports. The first was a description of the main results of the analyses described so far. In English, to facilitate their sharing among the consortium. The second was a synthesis of these results introducing some interpretative insights to support developing the following phase.
(To be continued)
Authors: Sonia Brondi (Observa) & Carolina Moreno (UVEG)
I commenti sono chiusi.